Input:
Coarse:
Fine:
DIPS:
We present DIPS, a novel approach to Cantonese word segmentation that addresses the challenges of balancing model size, inference speed, and accuracy while accommodating diverse segmentation standards and supporting named entity recognition. Our method combines fine-tuning, knowledge distillation, structured pruning, and quantization to create a compact and efficient model. DIPS introduces a new segmentation scheme that captures nuanced word boundaries, enabling flexible multi-criteria segmentation and entity identification. Experimental results show that DIPS achieves comparable performance to ELECTRA Small on standard benchmarks while being 17 times smaller (3 MB) and 3 times faster (0.13 ms/token on CPU). DIPS offers a practical solution for Cantonese NLP tasks, particularly in resource-constrained environments and real-time applications. The model is available as open-source libraries published on PyPI and NPM. Source code and pretrained models are available on GitHub.
Chinese word segmentation faces two major challenges: balancing size, speed, and accuracy, while also accommodating diverse segmentation standards.
To illustrate these challenges, let's examine the popular HanLP toolkit, which offers 3 types of segmentation models:
While transformer models are the default in HanLP due to their versatility, their size and computational requirements hinder widespread adoption. For instance, HanLP demos for these models run on servers and developers are required to request an API key for sustained access. Consequently, lighter-weight approaches like Hidden Markov Models remain the most popular. At around 5MB in size, Jieba's success stems from its superior performance compared to dictionary segmentation while maintaining a manageable footprint.
The challenge is further compounded by diverse segmentation standards, which fragment the limited training data and necessitate multiple models for different standards. HanLP trains a model for each corpus (e.g., CTB9, MSR, PKU) as they feature distinct segmentation standards. Recent work by He et al. (2018) and Chou et al. (2023) trains a single model for all standards, approaching multi-criteria Chinese word segmentation as a multi-task learning problem. However, users often struggle to choose the most suitable standard, cannot mix and match different standards, and lack insight into the differences between them.
These challenges are even more pronounced in Cantonese NLP, where training data is much more limited. To address these issues, we propose DIPS, a multi-criteria Cantonese word segmentation toolkit that is slim, fast, and accurate. DIPS achieves comparable performance as ELECTRA Small while maintaining a size comparable to Jieba (only ~3MB). Benefiting from a combination of model compression techniques, its inference speed is more than 3x faster than ELECTRA Small, making DIPS a practical segmentation solution on web and mobile.
Moreover, DIPS adopts a multi-criteria segmentation format recently proposed by Lam et al. (2024). This format naturally encompasses both coarse and fine-grained segmentation levels while also marking word category boundaries, morpheme boundaries, and named entities. As a result, DIPS can accomodate for various segmentation needs in natural language processing, information retrieval, and language education.
Toasty News conducted a comprehensive survey of existing Cantonese word segmentation tools, comparing their performance across various Cantonese and Chinese datasets. For our analysis, we'll focus on two particularly insightful datasets in the Universal Dependencies format for Hong Kong Cantonese and Written Chinese (Wong et al., 2017). These datasets are especially valuable as they showcase both languages in formal and informal contexts, providing a balanced representation. Moreover, their parallel nature allows for a direct comparison of word segmentation capabilities between Cantonese and Chinese, offering a clear picture of each model's cross-lingual performance.
Regarding training datasets, Chinese boasts a rich selection of segmentation corpora. Among these, four datasets from the Second International Chinese Word Segmentation Bakeoff (Emerson, 2005) are particularly noteworthy. These datasets, sourced from Academia Sinica (AS), City University of Hong Kong (CU), Peking University (PKU), and Microsoft Research (MSR), serve as standard training datasets for Chinese word segmentation research and development. In contrast, the landscape for Cantonese is notably sparse compared to Chinese. The Hong Kong Cantonese Corpus (HKCanCor) stands out as the sole significant open-source Cantonese corpus with word segmentation. For comparison, the largest Chinese dataset AS contains 4,904,120 tokens and the smallest Chinese dataset PKU contains 991,815 tokens. In comparison, the HKCanCor dataset only contains 153,654 tokens, which is 6x smaller than PKU and 30x smaller than AS. Due to the relative abundance of Chinese data, prior work usually jointly train on both languages to increase the training size.
| Tool | UD Yue HK | UD Zh HK |
|---|---|---|
| Toasty News ELECTRA HK Small | 94.68% | 92.77% |
| Toasty News ELECTRA HK Base | 94.62% | 93.30% |
| Toasty News ELECTRA HKT Base | 94.04% | 93.27% |
| Toasty News ELECTRA HKT Small | 93.89% | 93.14% |
| CKIP BERT Base | 89.41% | 92.70% |
| cantoseg | 86% | 84% |
| PyCantonese | 86% | 84% |
| CKIP BERT Tiny | 85.02% | 92.07% |
| pkuseg | 83% | 92% |
| jieba | 82% | 84% |
Table 1 shows five groups of models:
Among the models tested, transformers trained exclusively on Cantonese segmentation datasets (group 1) exhibit the highest performance on UD Yue HK. They are closely followed by models trained on mixed Cantonese and Chinese datasets (group 2). In contrast, transformers trained solely on Chinese segmentation datasets (group 3) show a marked decrease in performance when applied to Cantonese. Cantoseg, an HMM model, performs on par with dictionary segmentation, owing to its incorporation of dictionary data from HKCanCor. It's worth noting that transformer models trained on Cantonese data demonstrate good generalization to Chinese, likely due to their pretraining on substantial amounts of Chinese text.
A closer look at segmentation errors reveals that some are false alarms due to differing standards between datasets. For instance, HKCanCor splits proper names (e.g., 黎 lai4 + 明 ming4, "Leon Lai"), while UD does not. These differences, as detailed by Lam et al. (2024), complicate accurate model evaluation. Furthermore, existing multi-criteria methods prove ineffective in this context, as HKCanCor and UD Yue are the only Cantonese datasets available. When UD Yue reserved for testing, HKCanCor is the sole Cantonese dataset available for training.
While transformer models demonstrate superior performance, their substantial memory and computational requirements impede widespread adoption. To address this challenge, researchers have developed various techniques for model compression and accelerated inference. Three popular approaches are knowledge distillation, quantization, and pruning.
Sanh et al. (2020) first applied knowledge distillation to BERT in their work on DistilBERT, which involves training a smaller model to emulate a larger one. This technique successfully reduced the size of a BERT Base model by 40% while retaining 97% of its language understanding capabilities and achieving 60% faster inference.
Quantization, another effective technique, reduces the precision of model parameters. It can be broadly categorized into two types: Quantization-Aware Training (QAT) and Post-Training Quantization (PTQ) (Hu et al., 2022). QAT methods like Q8BERT (Zafrir et al., 2019) quantize BERT's weights and activations to 8-bits by introducing quantization error during fine-tuning. TernaryBERT (Zhang et al., 2020) uses 3-bit weights and 8-bit activations, overcoming performance degradation through knowledge distillation. BinaryBERT (Bai et al., 2020) further refines TernaryBERT by binarizing weights and quantizing activations to 4-bit, though this process is time and resource-intensive.
PTQ methods generally do not require extra fine-tuning or retraining to compensate for quantization errors. Hu et al. (2022) evaluated three PTQ approaches on BERT-Base and BERT-Large: Linear Quantization (LQ), Analytical Clipping for Integer Quantization (ACIQ), and Outlier Channel Splitting (OCS). They found that OCS could quantize BERT-Base and BERT-Large to 3-bits while retaining 98% and 96% of their performance on the GLUE benchmark, respectively. Popular machine learning libraries have also developed their own quantization methods. For instance, GGML, a tensor library for transformer models, supports at least 17 post-training quantization methods with various size and performance trade-offs. The Q4_0 method, a 4-bit round-to-nearest quantization, is generally considered the most intensive quantization type with acceptable performance. It can compress a 7B transformer model from 26GB in F32 full-precision to 3.5GB at the cost of a 0.2499 perplexity increase.
Pruning, another compression technique, was pioneered for modern neural networks by Han et al. (2015). Their method involved removing unimportant connections and retraining the network to fine-tune the remaining connections' weights. This approach reduced AlexNet's parameters by a factor of 9x on the ImageNet dataset without sacrificing accuracy. However, unstructured sparsity patterns are challenging to support efficiently on modern CPUs and GPUs. Consequently, structured pruning, which removes blocks of weights at once, has gained popularity (Blalock et al., 2020). For transformer models like BERT, one straightforward structured pruning method is dropping entire transformer layers. Sajjad et al. (2022) systematically evaluated different layer-dropping strategies on several BERT models and successfully pruned up to 40% of the model while maintaining up to 98% of the original performance by simply removing the top half of the transformer layers.
Our methodology for efficient multi-criteria Cantonese word segmentation involves 3 key steps: fine-tuning, model distillation, and quantization.
First, we approach word segmentation as a token classification task. We fine-tune Cantonese ELECTRA models on a new version of the HKCanCor corpus, annotated by Lam et al. (2024). This annotation scheme introduces a more nuanced approach to word boundaries, using spaces ( ), dashes (-), and pipes (|) to denote different types of separations:
To accommodate this refined annotation, we extend the traditional BI (Beginning, Intermediate) scheme. Our new DIPS scheme further categorizes the Beginning character into three types: Dashes, Pipes, and Spaces, corresponding to the separator preceding it. This allows our models to capture the nuanced segmentation information present in the new annotation.
At inference time, our model offers users a flexible range of segmentation options. Building upon the DIPS scheme, we provide both coarse and fine-grained segmentation levels. Users can choose to split results using only spaces for coarse segmentation or utilize all separator types for more fine-grained results. Furthermore, the fully annotated output remains accessible, enabling advanced applications such as named entity extraction from pipe-separated tokens. This versatility ensures that our model can adapt to various user needs and downstream tasks.
Here's an example to illustrate our DIPS segmentation scheme. Note how the named entity 張先生 (Mr. Zoeng) is
separated by a pipe and the affectionate prefix 阿 is attached to the entity via a dash.
Sentence: 阿張先生嗰時好nice㗎
DIPS: 阿-張|先生 嗰-時 好 nice 㗎
Fine: 阿 張 先生 嗰 時 好 nice 㗎
Coarse: 阿張先生 嗰時 好 nice 㗎
Labels: SDPISDSSIIIS
Gloss: Mr. Zoeng was so nice at the time.
Second, we combine knowledge distillation with structured pruning to achieve significant model compression while minimizing performance degradation. We distill an ELECTRA Base model into a smaller ELECTRA model with half of its layers removed. The number of layers to drop was determined empirically based on the training loss during fine-tuning.
Finally, we apply Q4_0 quantization using GGML to further compress the model and increase inference speed. This step prepares the model for efficient deployment across various platforms, enabling fast CPU and GPU inference.
To evaluate our model's performance, we use the standard token F1 score. To accurately evaluate our model on the UD datasets that only provide space-segmented tokens, we leverage the flexibility of our DIPS scheme to dynamically accommodate the UD standard on a token level during evaluation. This works by first creating a coarse-to-fine token mapping for our segmentation result, converting matched coarse tokens in the UD sentence to our fine tokens, and finally comparing the transformed ground truth with our fine tokens. Here's an example to illustrate the evaluation process:
Sentence: 阿張先生嗰時好nice㗎
Observe how the hypothesis aligns with the reference, despite neither the coarse nor fine versions matching it
exactly. This discrepancy arises because the hypothesis combines elements of both segmentation levels. By
applying a coarse-to-fine mapping to the reference, we can more accurately evaluate the model's performance
without unfairly penalizing it for segmentations that are technically correct but differ in granularity.
Hypothesis: 阿-張|先生 嗰-時 好 nice 㗎
Hypothesis (Fine): 阿 張 先生 嗰 時 好 nice 㗎
Hypothesis (Coarse): 阿張先生 嗰時 好 nice 㗎
Coarse to Fine: 阿張先生 => 阿 張 先生, 嗰時 => 嗰 時
Reference: 阿張先生 嗰 時 好 nice 㗎
Reference (Mapped): 阿 張 先生 嗰 時 好 nice 㗎
We investigate the effect of multiple axes on the performance vs size tradeoff:
Our experimental process consists of 4 steps:
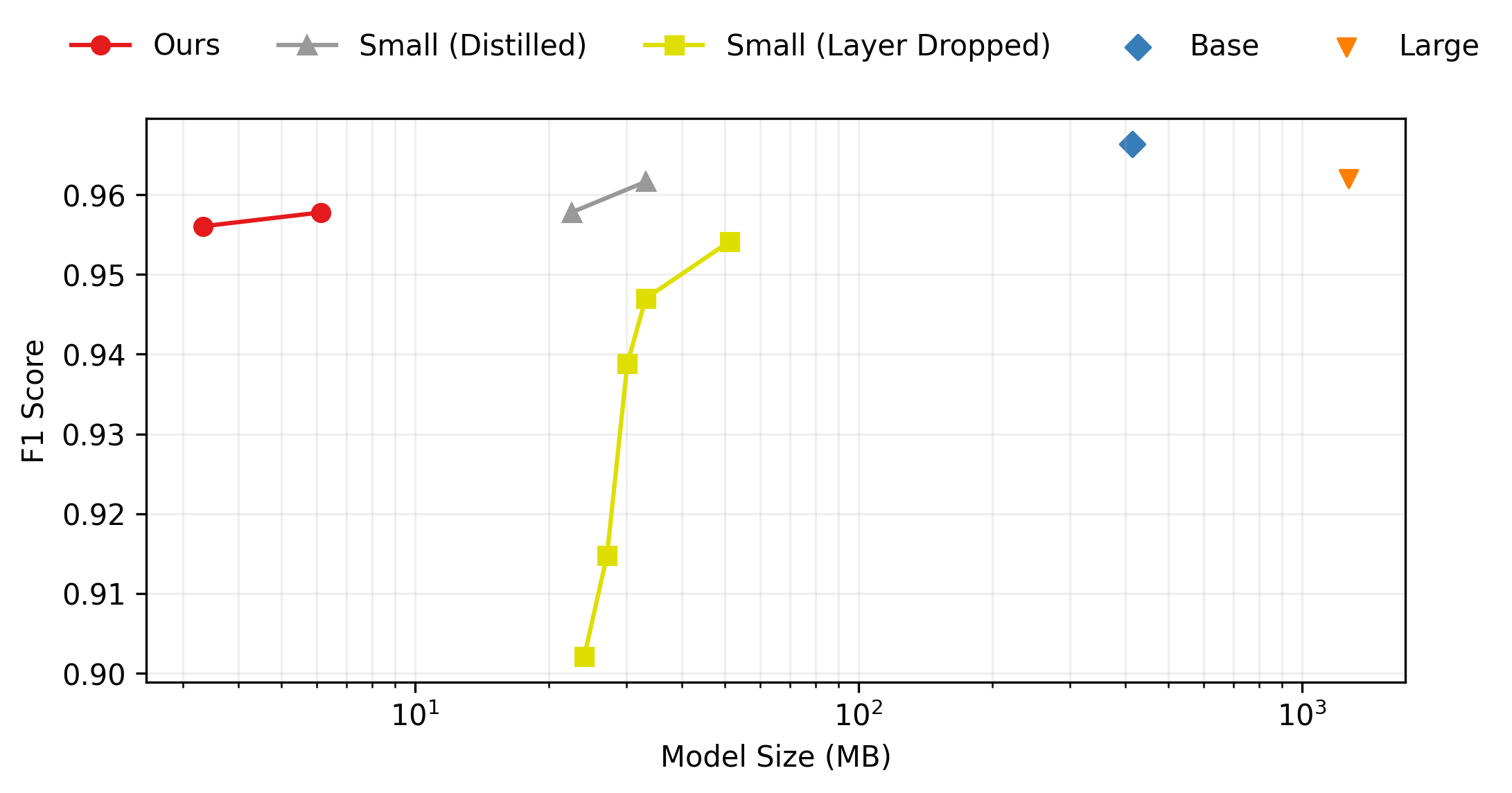
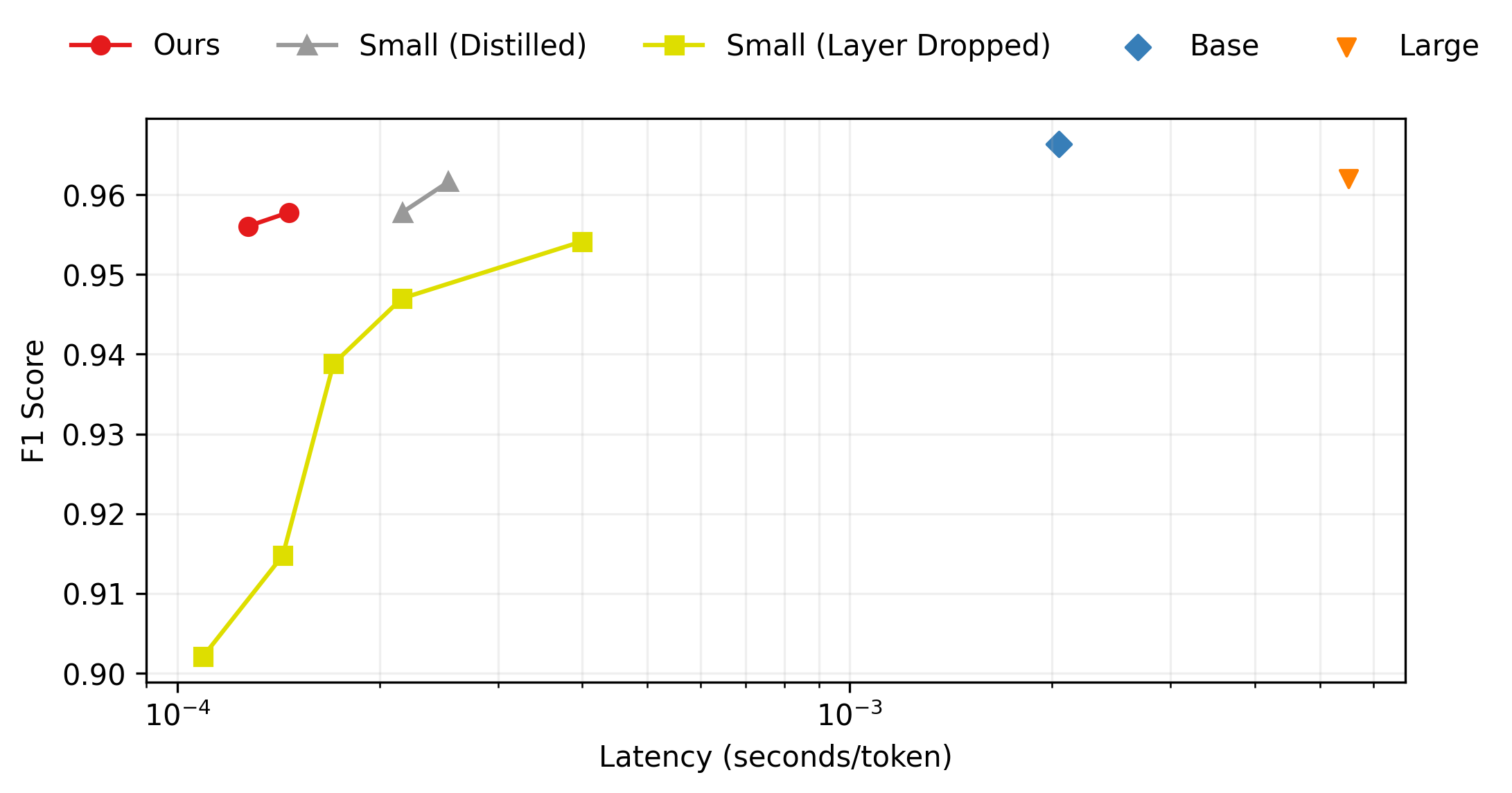
Figure 1 shows the performance vs size for the various configurations. Figure 2 shows the performance vs latency for the same set of configurations, tested on the M1 Max CPU with 10 cores. Table 1 shows the full statistics on both UD datasets for all configurations tested.
| Model Size | Layers Dropped | Distilled | Truncated Vocab | Quantization | Size (MB) | Latency (ms/tok) | UD Yue F1 | UD Zh F1 |
|---|---|---|---|---|---|---|---|---|
| Large | 0 | No | No | None | 1272 | 5.51 | 0.9620 | 0.9571 |
| Base | 0 | No | No | None | 414 | 2.05 | 0.9663 | 0.9533 |
| Small | 0 | No | No | None | 51 | 0.40 | 0.9541 | 0.9401 |
| Small | 6 | No | No | None | 33 | 0.22 | 0.9470 | 0.9267 |
| Small | 7 | No | No | None | 30 | 0.17 | 0.9388 | 0.9147 |
| Small | 8 | No | No | None | 27 | 0.14 | 0.9148 | 0.8557 |
| Small | 9 | No | No | None | 24 | 0.11 | 0.9021 | 0.8257 |
| Small | 6 | Yes | No | None | 33 | 0.25 | 0.9616 | 0.9454 |
| Small | 6 | Yes | Yes | None | 23 | 0.22 | 0.9578 | 0.9401 |
| Small | 6 | Yes | Yes | Q8_0 | 6 | 0.15 | 0.9578 | 0.9403 |
| Small | 6 | Yes | Yes | Q4_0 | 3 | 0.13 | 0.9560 | 0.9382 |
Analyzing the trends in Table 2, we can observe several key points:
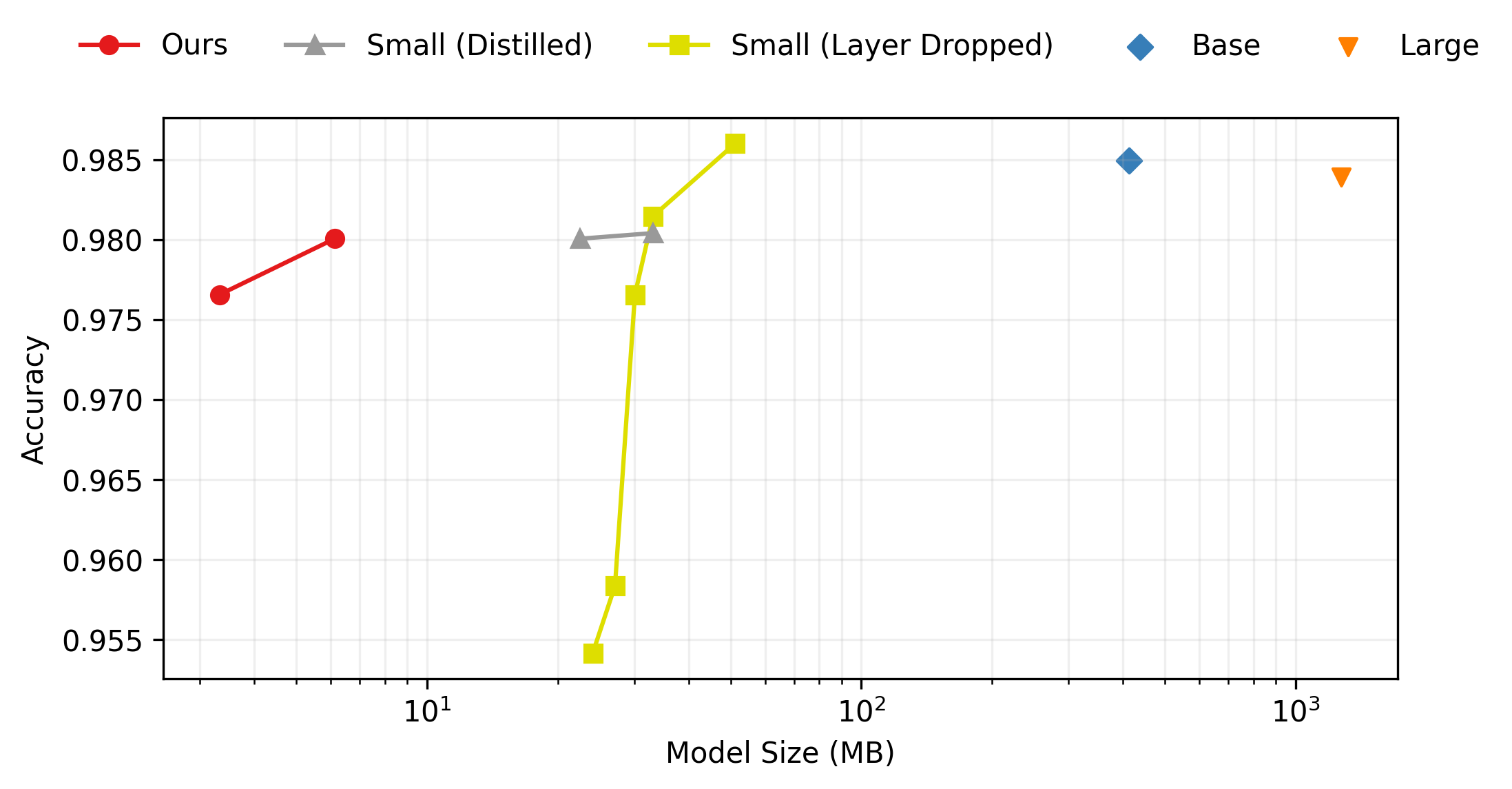
Figure 3 complements Figure 1 and shows similar performance vs size tradeoff on the HKCanCor test split. The notable exception is that ELECTRA Small outperforms Base, which is likely due to the smaller model overfitting during fine-tuning.
In conclusion, our DIPS model for Cantonese word segmentation demonstrates a remarkable balance between performance, size, and latency. Through a combination of techniques including layer dropping, distillation, vocabulary truncation, and quantization, we have developed a model that is 17 times smaller and 3 times faster than the ELECTRA Small model, while maintaining comparable performance. This significant reduction in size and improvement in speed makes our model highly suitable for deployment in resource-constrained environments and real-time applications.
Try our model with pip install pydips or npm install dips.js! Mobile implementations
are in the works - stay tuned!
We would like to thank Charles Lam, Chaak Ming Lau, and Jackson L. Lee for their work on creating the first multi-tiered cantonese word segmentation corpus. Without their work, this project will not be feasible. We would also like to thank Toasty News for open sourcing their pretrained models, scripts, and evaluation results, which provided a strong foundation for this project.